Four Days to Five Minutes: Inside the NightGuides Build
Four days of manual report-writing, gone. After every event, NightGuides submits two files and a finished report lands in about five minutes. This is the build under that result: the architecture, the decisions that made it reliable, and the one step I deliberately kept human.
Ashraf Daoud
AI Automation Engineer
The problem was a weekend, not a feature
NightGuides runs nightlife safety across five Amsterdam venues. Every shift, the team logs what happens on the floor in a WhatsApp group: medical calls, removals, refusals, anything a venue needs on record. The raw account of the night lives in that thread.
Turning that thread into the report a venue actually reads used to take about four days. Someone scrolled back through the chat, reconstructed the night by hand, sorted what mattered from the noise, and wrote it up. Multiply that across five venues, some of them running several events in a single weekend, and reporting becomes a part-time job nobody signed up for.
Four days of lag on a safety record is not an admin cost. The review meeting waits on one person's data entry. The people who worked the floor stay up writing instead of resting. The clearest account of an incident arrives days after the night it describes, once the detail has already started to fade.
So the brief was narrow. Take the night that already exists in the chat and turn it into the venue's report, without a person reconstructing it by hand, and without dropping anything that matters.
Same night. Four days by hand, or five minutes.
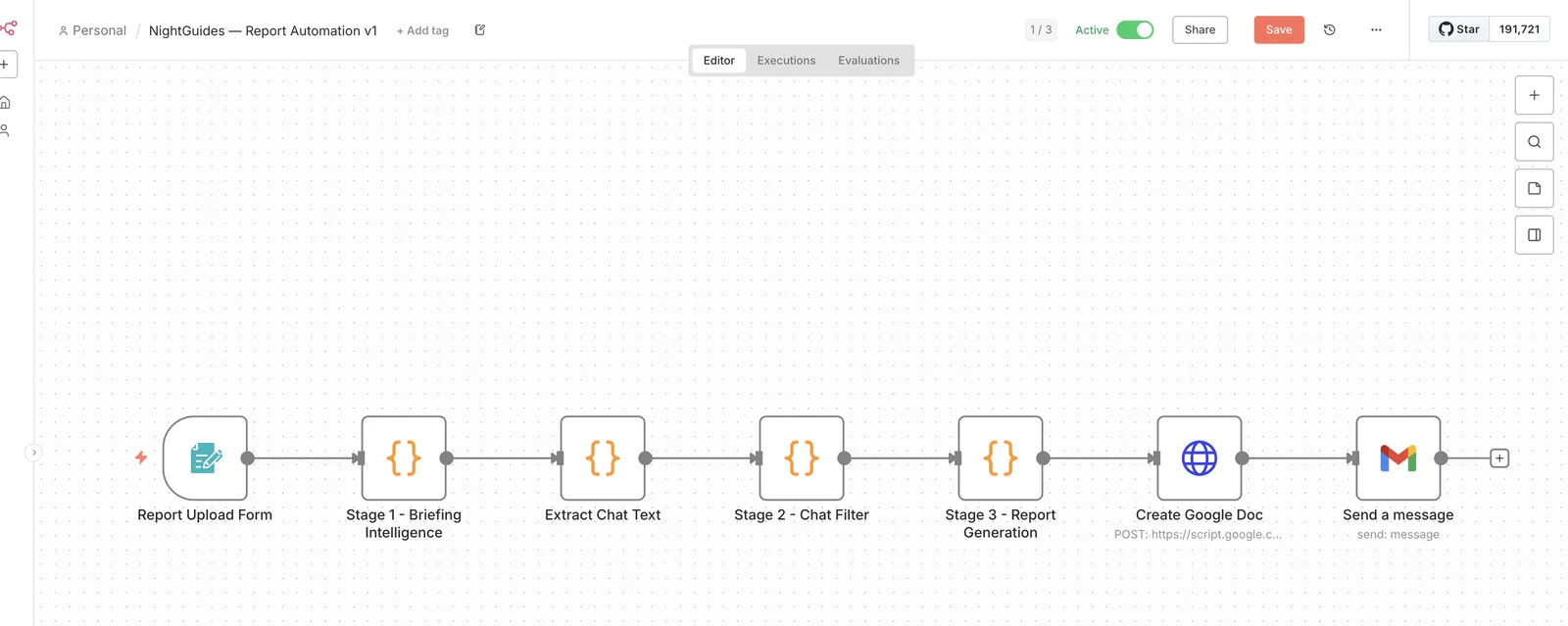
The shape of the system
The live prototype, running. Synthetic placeholder text, no real incident content.
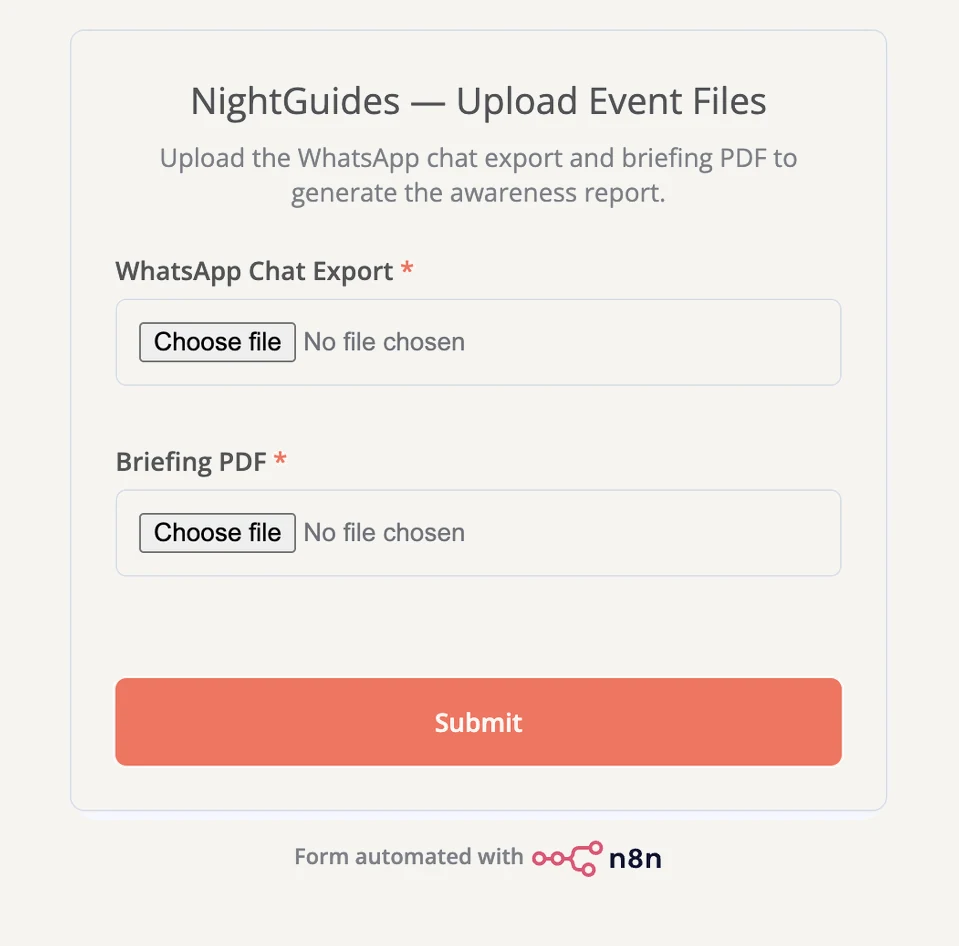
The pipeline runs on n8n, self-hosted on a private server. One form is the only manual entry point. After an event, the team submits two things: the WhatsApp chat export and the event briefing as a PDF. Everything past the submit button is automatic, up to the final step, which I will come back to because it is the most important one.
End to end, it is six stages: intake, a parse-and-filter step, two separate Claude passes (one to extract, one to write), document assembly, and delivery. Each stage does one job and hands clean output to the next. That separation is the entire reliability story, so it is worth walking through stage by stage rather than as a black box.
The live workflow, running on a private n8n instance: one form in, through the stages, out to a Google Doc and an email.
The briefing PDF is the control file
The chat export is the raw material. The briefing PDF is what tells the system how to read it.
Two things get pulled from the briefing before anything else runs: which venue the event was, and which date it ran on. The date matters more than it looks. A WhatsApp export is not one night. It is the entire group history, every message the team has ever sent. Hand all of that to a model and ask for one night's report and you get a confident, wrong answer. So the system reads the date from the briefing and filters the export down to the correct weekend before any model sees it.
The win for the owner is that nobody prepares anything. The founder uploads two files she already has and never thinks about scope. The system decides what counts as "this event" from a document the team already produces, instead of asking them to tag, trim, or format the chat first. The work bends to how the team already operates, not the other way round.
The only manual step. The team uploads two files they already have, and never thinks about scope.
When one weekend holds several events
One of the venues runs multiple events across a single weekend, sometimes back to back. A flat date filter is not enough there, because Friday's incident and Saturday's incident sit in the same thread a few hours apart.
The system separates them using two signals already present in the chat: message timestamps, and the short markers staff post when they clock in and out of a shift. Those clock-in lines act as anchors. They tell the system where one event's coverage begins and the previous one ends, so a row from Saturday night does not quietly end up in Friday's report.
The point worth taking from this: most of the reliability did not come from a cleverer prompt. It came from finding signals the team was already producing and using them as structure. The data to disambiguate the weekend was always there. The build just had to read it the way a person would.
Stage one: turn a chat into structured facts
The first Claude pass does one job. It reads the filtered chat and returns structured incidents, not prose. Each incident carries its time, its category, its severity, and a short account of what happened. The output of this stage is data, not paragraphs.
This is the decision that separates a system you can trust from a demo. The obvious build is one instruction: hand the model the chat, ask for the finished report. It shows well in a five-minute demo. It holds up badly on a busy night, because reading a messy thread and composing a clean report are two different cognitive jobs. Ask one pass to do both and each gets done at half attention. The seams show on exactly the nights you most need it to hold.
Splitting extraction from writing fixes that. The extraction pass can be checked on its own terms, as a list of facts. The writing pass starts from agreed facts rather than raw noise. And when a report ever reads slightly off, the fault is easy to locate, because there are two inspectable stages instead of one opaque step.
A two-second input convention does most of the heavy lifting
There is a quiet input-layer decision that carries more of the accuracy than anything in the model calls. The team can mark a message with a short prefix to flag it as a reportable event of a given kind. When they do, extraction is close to exact, because the message is self-labelling. When they do not, the model falls back to reading the message in context, which is good, but not perfect.
The design choice was to reward the convention without depending on it. I did not put a rigid intake form in front of a team working a live floor at two in the morning. A two-second prefix is something a shift lead can actually do mid-event. A structured form is not. So the system runs fine on plain narrative messages and runs near-perfectly when the convention is used, and it gets more accurate over months as the habit spreads, with no change on the system side.
For an owner-operator that graceful degradation is the difference between a system that survives real use and one that breaks the first time someone is too busy to follow the rules. Real teams do not follow the rules on the worst nights. The build assumes that.
Two passes, not one. The first turns the chat into structured incidents, the second writes them up.
Stage two: write the report the team already uses
The second Claude pass takes the structured incidents and writes them up in the exact format the venue already reviews on. Not a generic template that would force the team to change how they read a report to suit the tool. The format bends to NightGuides.
Because this pass starts from clean, structured facts rather than the raw thread, its job is composition, not detective work. It is deciding how to present a known set of incidents, not guessing what happened. That is why the two-pass split is not academic tidiness. It is what lets each call be good at one thing, and it is what makes the output consistent enough to put in front of a venue week after week.
A side effect of building it this way: the system can run backwards. Because it reads the same two files the team already keeps, months of past events that were never properly written up can be processed into a consistent library of reports, after the fact, in an afternoon.
Assembly and delivery
The written report is formatted, created as a document in Google Docs, and delivered to the team by email as a link. The founder's entire experience of the system is three steps: upload two files, receive an email, open a finished document. Every piece of complexity above sits behind that.
One number worth keeping honest. The five minutes is processing time, from submit to a finished document. The report reaches the venue partner within about 48 hours of the event, against the four days it took before. Both numbers are real and they measure different things. The five minutes is what the system removed from a person's plate. The 48 hours is what the venue now experiences.
The step I kept human
Here is the part I deliberately did not automate.
The body of the report is generated. The conclusion, the judgement about what the night meant and what should change, is reviewed and signed off by a shift lead before it reaches the venue. The model drafts a strong conclusion. A person owns it.
That is a choice, not a limitation. The system could finalise the whole thing untouched, and it would usually be right. But a safety report is not the place to take the human off the judgement call. The right division of labour is to automate the four days of reconstruction, the part that was only ever mechanical, and keep a person on the part that carries responsibility. Faster reporting should give the team more attention for the decisions that matter, not remove them from those decisions.
This is what "stay human, scale smart" actually looks like in a build. It is not a slogan at the bottom of a page. It is a sign-off step in the pipeline.
The body is generated. The judgement is signed off by a person before it ships.
Where the data lives, and why that was in the spec
Every part of this runs on infrastructure NightGuides controls: n8n self-hosted on a private server, with the model calls running under terms where the data is not used to train anything. The incident records stay on their server.
For a lot of automation, that is a nice-to-have. For this work it was a requirement from the first conversation. Incident reports name people and describe what happened on a venue floor on a specific night. That is not data you route through a system that learns from it, and it is not data you leave sitting on someone else's platform. Who controls the records is part of the specification, designed in at the start, not a privacy note bolted on at the end.
The records stay on infrastructure NightGuides controls. The model processes, it does not learn.
What changed
The numbers, all from the live system:
4 days → 5 minutesShift end to a finished report
14 daysKickoff to a working prototype
5 venuesLive on one system across Amsterdam
1 formDrives the entire pipeline
30 daysSupport window after delivery, used for real
The fourteen days matter as much as the five minutes. A founder does not want a six-month transformation programme. She wants to see the thing work before she has stopped thinking about the problem. Fast enough to keep trust intact, built carefully enough to hold once it does.
Here is how Mila Haj Kasem, who founded and runs NightGuides, put it:
“
What used to take four days takes five minutes. Our review meetings happen earlier in the week, and the people who worked the shift get to rest instead of writing it all up.
Mila Haj Kasem
Founder and Director, NightGuides
If your team rebuilds the same report every week
Most teams have one of these jobs hiding in plain sight. A repeated, rules-based task that someone reconstructs by hand because the raw material lives in the wrong place: a chat thread, an inbox, a stack of forms. It rarely feels worth fixing, right up until you count the days.
That is the kind of work worth mapping first. The free scan at ashrafdaoud.com/find-your-leverage is built to find it: the four-day jobs sitting in your week, before any build and before any commitment.